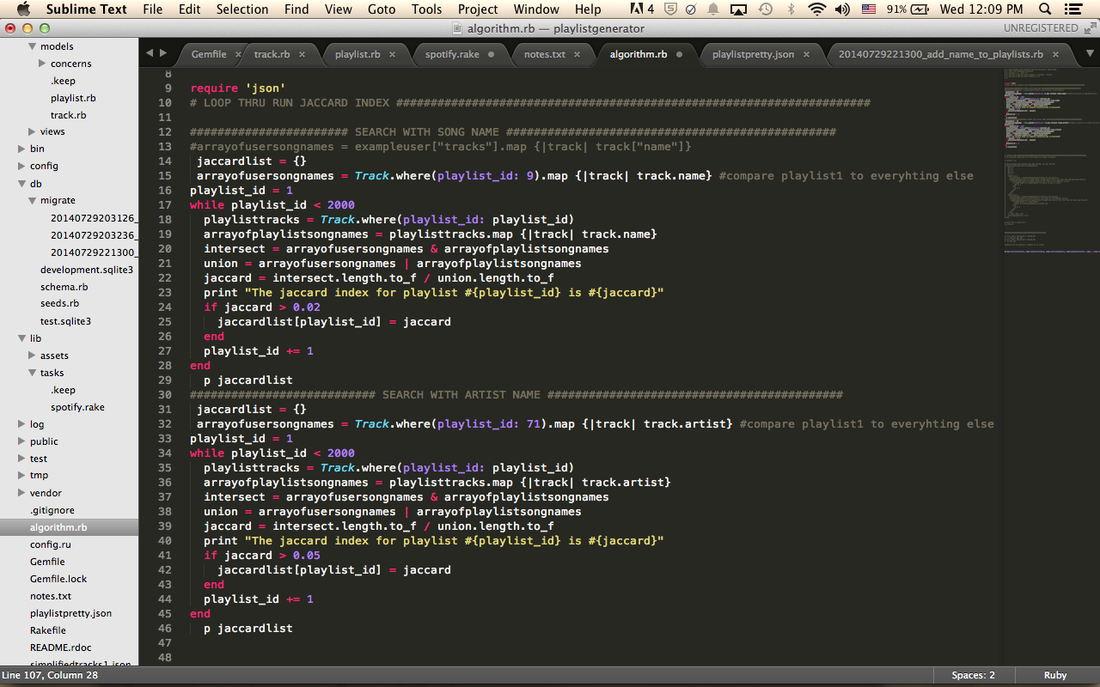
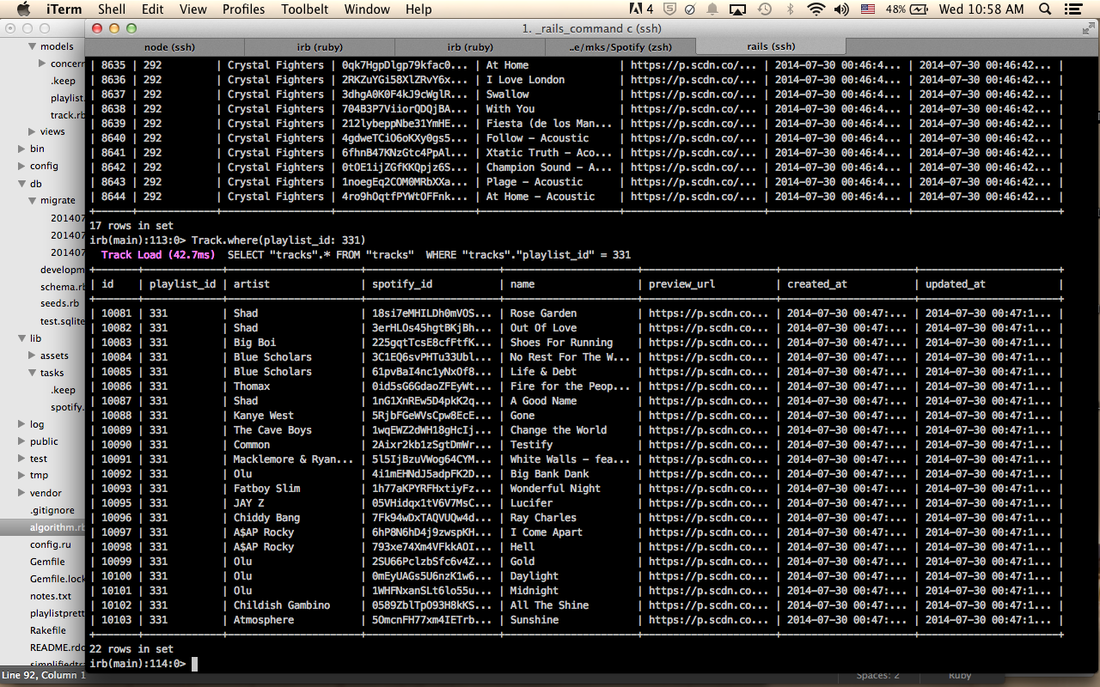
The code for the recommender ended up being pretty simple. You loop through the playlist that the user wants to match to and loop through each playlist in the database. For now I have about 80,000 tracks in 2600 playlists. I basically added each user's username (got them from people that I'm friends with on fb) and made an AJAX call to get each playlist and download them into files every 0.2 seconds because the Spotify API limits the calls to 10 calls per second. If I get an error during the looping it quits and it's a pain in the butt so just to be sure I multiplied the amount of time to sleep between calls. After a couple hours of struggling with it randomly quitting (or my access token expiring) I downloaded all the info I need. Then I passed them into my sqlite database in Rails which took another hour. I then used the code I wrote to calculate the Jaccard similarity coefficient to test how it predicts using my own playlist. I first started by looking at the song names.
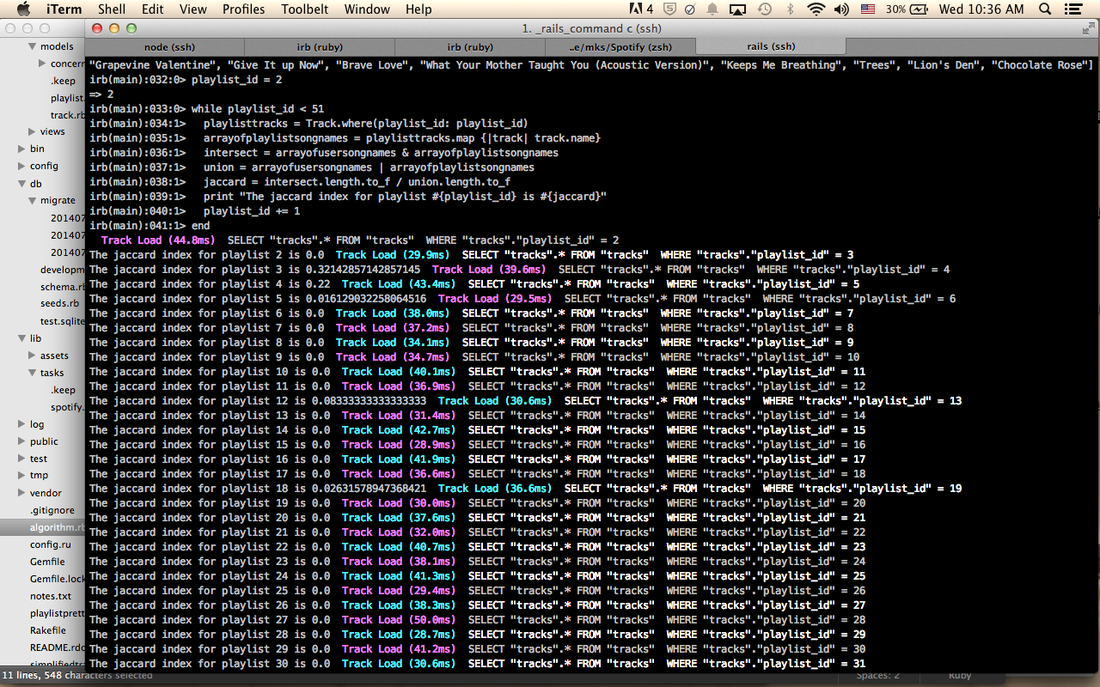
I looked at the playlists that had high Jaccard scores (over 0.02).
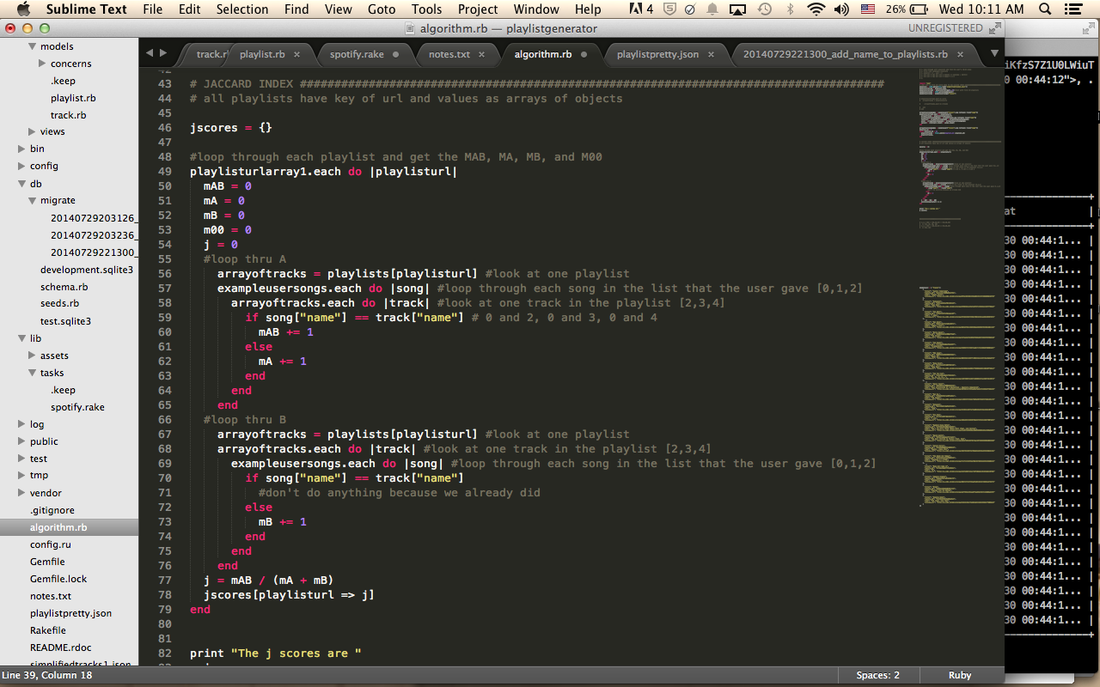
This caused some problems. Some predictions were okay, but others were way off. It also kept on recommending playlists that only had one artist (like their album), or it would recommend playlists where I didn't know any of the songs. This was because I used the song names and some song names have multiple artists. I wasn't satisfied with the results so I decided to change it to look at the artists instead. I predicted that this would at least eliminate the playlists that only had one artist because intersections and unions don't include duplicates.
This was great! Not only did I get more hits but my predictions were correct about eliminating albums and about half of the playlists that came up had songs I always listened to. I think I'll stick with this method and go back and fiddle with it later when I have time (like normalizations and creating clusters).
One problem I have with this right now is that it takes about 2 minutes to go through all 80,000 tracks. From the user's side, this is not good at all. I would have to somehow create a visual that shows the percentage done (which I can probably implement by keeping a counter), change my database to PostgreSQL instead of sqlite (sqlite is slower), make one database query (Track.all) instead of one for each playlist (which means I would have to save all the data in a hash then loop through that) or try to rewrite my algorithm to get a smaller big O. Considering the fact that I only have 3 more days to finish everything, I'll get back to that later. I have to finish the front end first!
I looked at the playlists that had high Jaccard scores (over 0.02).
This caused some problems. Some predictions were okay, but others were way off. It also kept on recommending playlists that only had one artist (like their album), or it would recommend playlists where I didn't know any of the songs. This was because I used the song names and some song names have multiple artists. I wasn't satisfied with the results so I decided to change it to look at the artists instead. I predicted that this would at least eliminate the playlists that only had one artist because intersections and unions don't include duplicates.
This was great! Not only did I get more hits but my predictions were correct about eliminating albums and about half of the playlists that came up had songs I always listened to. I think I'll stick with this method and go back and fiddle with it later when I have time (like normalizations and creating clusters).
One problem I have with this right now is that it takes about 2 minutes to go through all 80,000 tracks. From the user's side, this is not good at all. I would have to somehow create a visual that shows the percentage done (which I can probably implement by keeping a counter), change my database to PostgreSQL instead of sqlite (sqlite is slower), make one database query (Track.all) instead of one for each playlist (which means I would have to save all the data in a hash then loop through that) or try to rewrite my algorithm to get a smaller big O. Considering the fact that I only have 3 more days to finish everything, I'll get back to that later. I have to finish the front end first!


 RSS Feed
RSS Feed