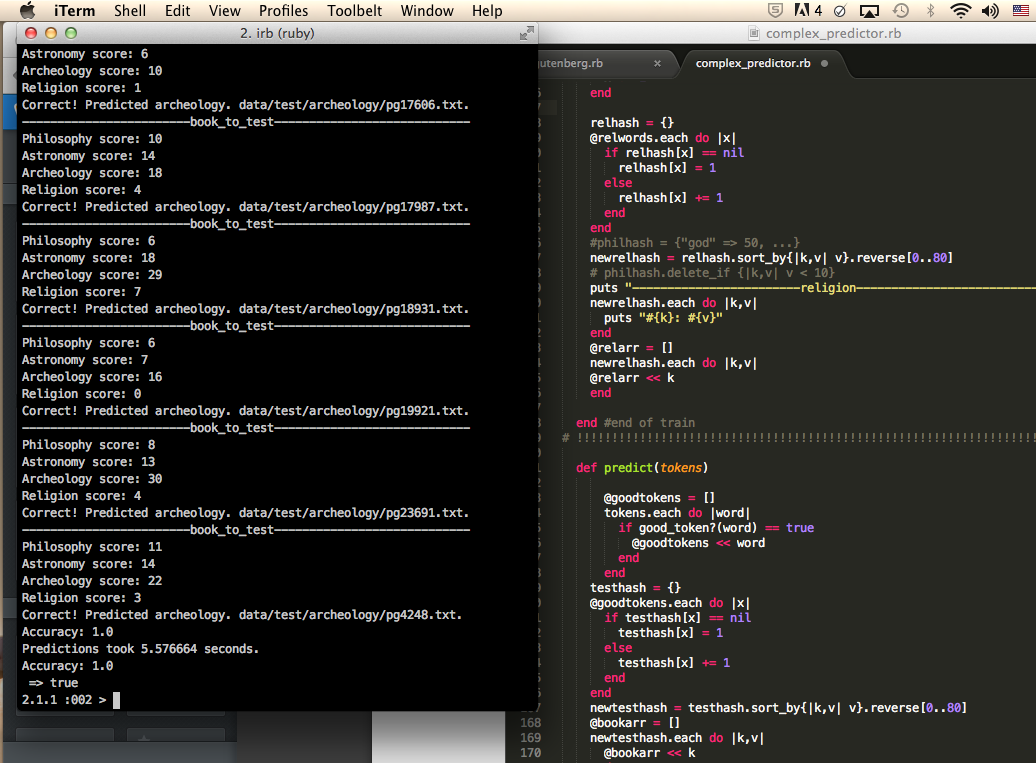
Tonight Alex and I got our project gutenberg to work! This is basically an app that could read a book and figure out what category (religion, philosophy, archeology, or astronomy) it belonged to. We wrote an algorithm that allowed the app to read a couple of sample books from each category and trained it to recognize what words were common in each category. We then wrote an algorithm for the books we passed through and came up with a scoring scheme to rank which category the book most likely belonged to. Although we had nested iteration which isn't best practice when focusing on time efficiency we also focused on minimizing the amount of tokens to loop through by using sorted arrays and hashes, we got ours to reach 100% accuracy with a pretty short run time!! I was proud of myself so I'll post proof :D. Tomorrow we start our mock hackathon and next week is our real one!
Update: picture below from our mock hackathon, we took a break to go watch the world cup and sachin went "too hard in the paint" :D
Update: picture below from our mock hackathon, we took a break to go watch the world cup and sachin went "too hard in the paint" :D


 RSS Feed
RSS Feed